DeepSeek V4 Released
DeepSeek V4 has officially launched with an open-source preview. There are two versions available:
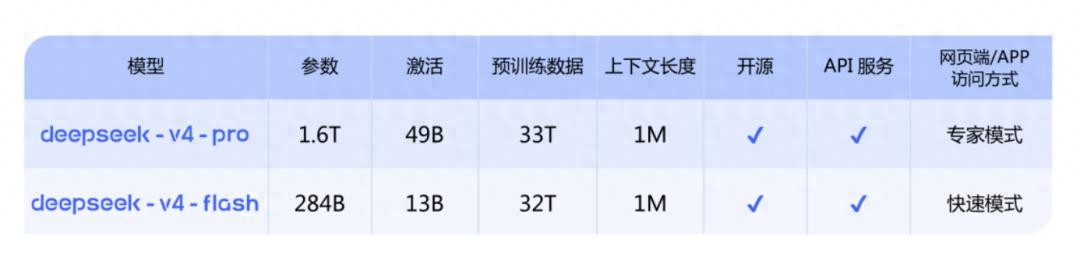
- DeepSeek-V4-Pro: Targets top closed-source models, with 1.6T parameters, 49B activations, and a context length of 1M.
- DeepSeek-V4-Flash: A smaller, faster economic version with 284B parameters, 13B activations, and a context length of 1M.
The official statement claims that DeepSeek V4 leads in agent capabilities, world knowledge, and reasoning performance within the domestic and open-source fields.
Currently, DeepSeek V4 is being used internally as an Agentic Coding model, with user feedback indicating a better experience than Sonnet 4.5, and delivery quality close to Opus 4.6 in non-thinking mode, though still trailing behind Opus 4.6 in thinking mode.
The official website and app have been updated, and the API service has also been refreshed. Notably, support for Huawei’s computing power will be available in the second half of the year.

Two Versions Released Together
DeepSeek V4 has launched both versions simultaneously.
V4-Pro
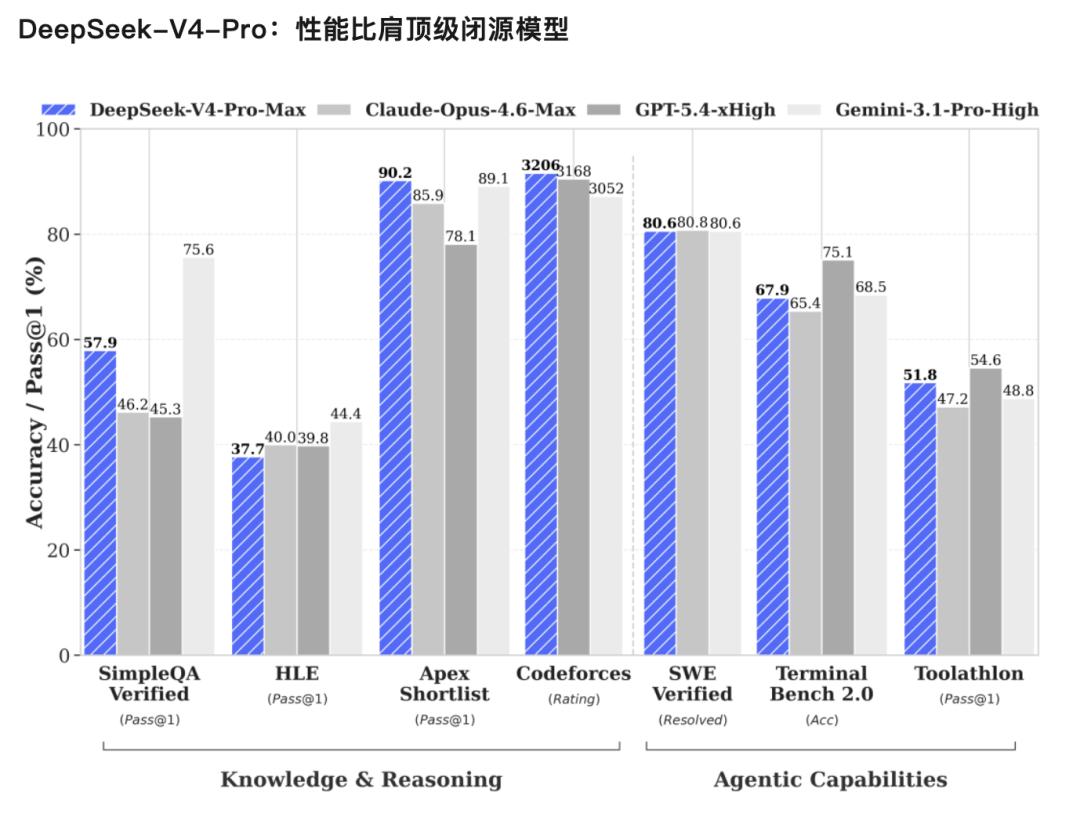
The performance of V4-Pro rivals that of top closed-source models. The official assessment includes three key points:
- Significantly Improved Agent Capability: In Agentic capability coding assessments, V4-Pro has reached the best level among current open-source models and performs excellently in other agent-related evaluations. In internal assessments, the agent coding mode of V4 outperformed Sonnet 4.5, with delivery quality approaching Opus 4.6 in non-thinking mode, but still falling short of Opus 4.6 in thinking mode.
- Rich World Knowledge: In world knowledge evaluations, DeepSeek-V4-Pro significantly outperformed other open-source models, only slightly behind the top closed-source model, Gemini-Pro-3.1.
- Top-Level Reasoning Performance: In assessments of mathematics, STEM, and competitive coding, DeepSeek-V4-Pro surpassed all publicly evaluated open-source models, achieving results comparable to the best closed-source models.
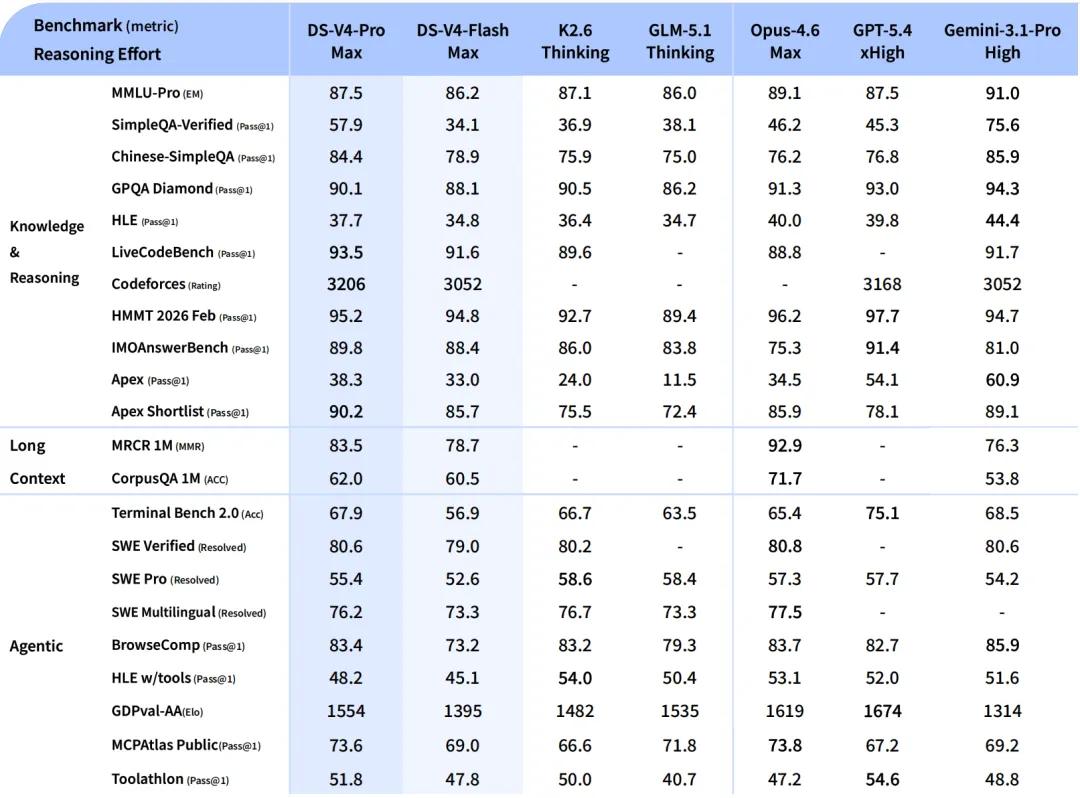
V4-Flash
The V4-Flash version is smaller and faster. Its reasoning capability is close to that of the Pro version, with slightly less world knowledge, but smaller parameters and activations, making the API more affordable.
In agent tasks, DeepSeek-V4-Flash performs comparably to DeepSeek-V4-Pro on simple tasks, but still shows a gap in more complex tasks.
In a test scenario, V4 also passed quickly.

However, in the classic biological scenario of the “desperate father,” DeepSeek-V4 failed to grasp the critical point of red-green color blindness (according to genetic rules, if a female is red-green color blind, her biological father must also be).

Standard Context Length of 1M
Notably, starting today, a 1M context length is standard for all official DeepSeek services. A year ago, 1M context was a unique feature of Gemini; other closed-source models were limited to either 128K or 200K, and very few open-source models could handle this scale.
DeepSeek has transformed the 1M context from a “premium feature” to a “basic utility.”
The release notes indicate that this was achieved through a new attention mechanism that compresses at the token dimension, combined with DSA sparse attention. This significantly reduces the computational and memory requirements compared to traditional methods.
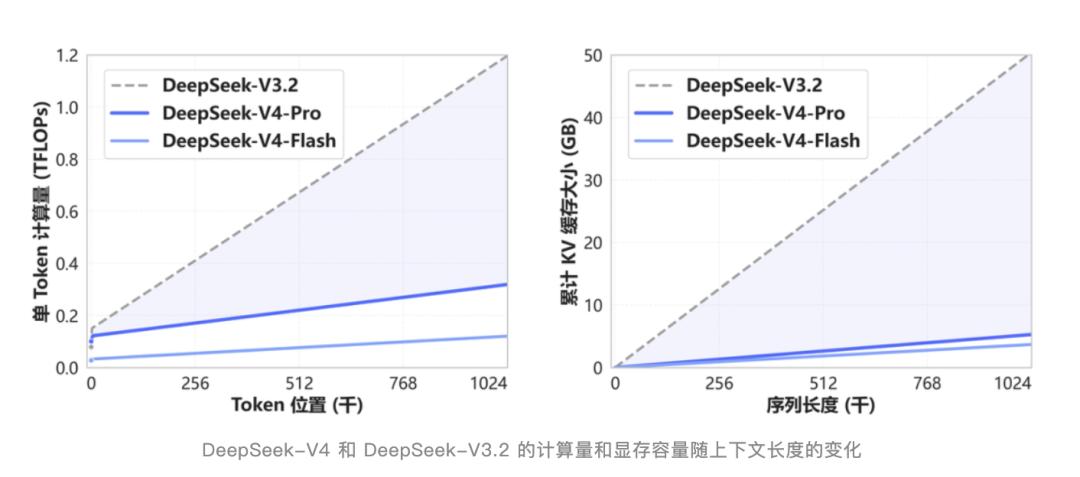
DSA is not a new term; it was first introduced in the V3.2-Exp update six months ago, which did not attract much attention at the time due to its similar performance to V3.1-Terminus, appearing as a minor update. In hindsight, it laid the groundwork for V4.
Optimized Agent Capabilities
For agents, V4 has been adapted and optimized for mainstream agent products such as Claude Code, OpenClaw, OpenCode, and CodeBuddy, resulting in improvements in coding tasks and document generation tasks.
The release notes also include an example of a PPT slide generated by V4-Pro within a certain agent framework.

API Pricing
The APIs for V4-Pro and V4-Flash have launched simultaneously, supporting both OpenAI ChatCompletions and Anthropic interfaces.
The base_url remains unchanged; simply modify the model parameter to deepseek-v4-pro or deepseek-v4-flash to call the respective version.
Both versions support a maximum context of 1M and include both non-thinking and thinking modes. In thinking mode, the reasoning_effort parameter can adjust the intensity, with two levels: high and max. The official recommendation is to use max for complex agent scenarios.
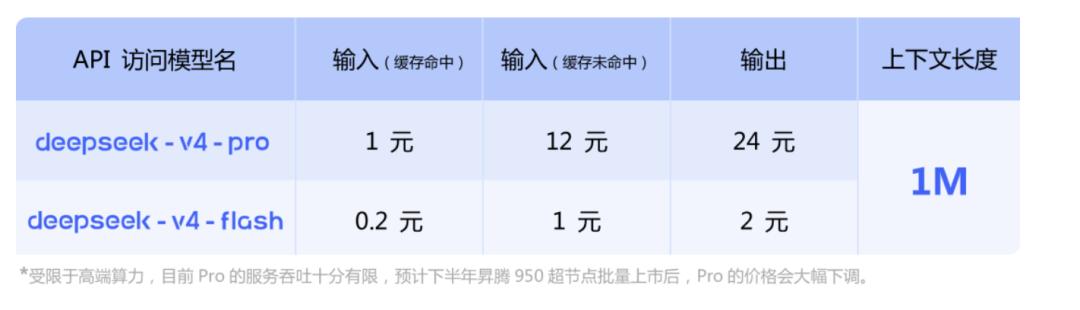
A key point is that support for Huawei’s computing power will be available in the second half of the year.
Additionally, old model names will be phased out. deepseek-chat and deepseek-reasoner will be discontinued three months later (on July 24, 2026). During this transition, these two names will refer to the non-thinking and thinking modes of V4-Flash, respectively.
For individual developers, the impact is minimal, requiring only a change in the model parameter. However, companies integrated into production environments will need to migrate within the next three months.
One More Thing
At the end of the release notes, DeepSeek included a quote:
“Do not be tempted by praise, nor frightened by slander, but follow the path and correct oneself.”
This is a line from Xunzi’s “Non-Twelve Sons.” In essence, it means not to be swayed by accolades or intimidated by criticism, but to move forward according to one’s own beliefs and to correct oneself.
In today’s context, this is quite interesting. Over the past six months, rumors about when V4 would be released, whether it would be delayed, if it had been surpassed by others, or if it had been resolved by Claude’s distilled data have circulated in both Chinese and English AI circles. Earlier this year, some even confidently claimed that V4 would be released before the Spring Festival, but it was not until the end of April that it finally arrived.
They did not respond to any of these rumors.
Then, on a Friday afternoon, they released V4, open-sourced it, updated the official website and app, and refreshed the API, while also noting that internal staff had already stopped using Claude.
There was no roadmap, no live streams, and no interviews.
The phrase “follow the path” sounds like a slogan, but when you consider the past six months of the seemingly uneventful V3.2 Exp version, the DSA sparse attention that laid the groundwork for V4, and the transition of 1M context from a premium feature to a standard utility, it all comes together.
DeepSeek has achieved this.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.